이번에 포스팅 할 내용도 정렬과 관련된 내용이다, 이전에 배웠던 알고리즘보다 더 성능이 뛰어나지만 그만큼 코드 구현이 어려웠다.
항상 드는 생각이지만 책을 보며 알고리즘의 작동 방식은 이해가 가지만 코드를 보며 해석하는건 너무 어려운것 같다. 그걸 내가 구현해내야한다는 것도 내가 넘어야 할 큰 산인것 같다.
셸정렬
셸정렬은 단순 삽입 정렬의 업그레이드 버전이라고 생각하면 쉽다. 단순 삽입 정렬은 옆 링크를 통해 알 수 있다. 여기
정렬 알고리즘 (1) - 버블정렬, 단순 선택/삽입 정렬
정렬 알고리즘은 정수의 배열을 오름/ 내림차순으로 정렬하기에 최적화 된 방법을 찾는 방식이다. 따라서 대소비교하는 수를 최소화 하는데에 초점을 두기 때문에 수식이 많아 코드를 이해하기
re-hwi.tistory.com
단순 삽입 정렬의 장점은 이미 순서대로 정렬된 값은 매우 빠르게 지나갈 수 있지만 먼 거리를 이동해야 하는 원소를 만났을 때에는 오래걸린다는 단점이 있다.
셸정렬은 이러한 단점을 보완한 알고리즘으로 먼저 정렬할 배열의 원소를 그룹으로 나눠 각 그룹별로 정렬을 수행한다. 그 후 정렬된 그룹을 합치는 작업을 반복하여 원소의 이동횟수를 줄이는 방법이다.
예시를 들어 쉽게 설명하면 아래 그림에서 보듯이 4칸을 기준으로 배열의 대소를 구분한 뒤 대소구분이 완료된 배열을 합치는 방식으로 구현한다.
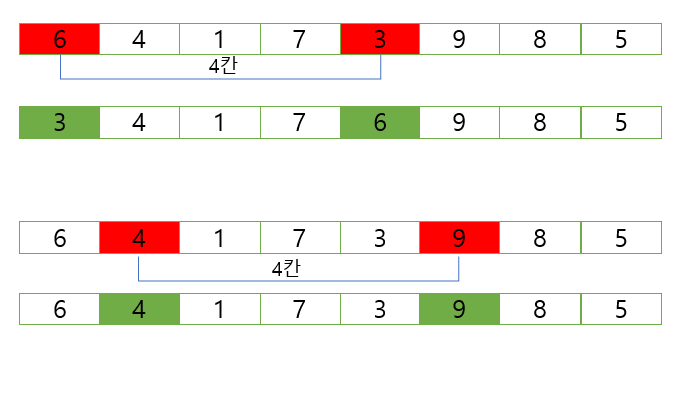
이런 방식을 이용하면 완전한 정렬이 되지 않지만 정렬된 상태에 가까워지기 때문에 마지막에 단순 삽입 정렬을 실행했을 때 큰 문제 없이 빠르게 정렬할 수 있다.
다음은 셸 정렬 알고리즘의 코드이다.
def shell_sort(a):
n = len(a)
h = n // 2 # h 값을 구하기
while h > 0:
for i in range(h, n): # 단순삽입정렬의 코드와 유사
j = i - h
tmp = a[i]
while j >= 0 and a[j] > tmp:
a[j + h] = a[j]
j -= h
a[j + h] = tmp
h //= 2
if __name__ == '__main__':
print('셸 정렬을 수행합니다.')
num = int(input('원소 수를 입력하세요.: '))
x = [None] * num
for i in range(num):
x[i] = int(input(f'x[{i}]: '))
shell_sort(x)
print('오름차순으로 정렬했습니다.')
for i in range(num):
print(f'x[{i}] = {x[i]}')하지만 셸 정렬을 할 때 h 값을 어떻게 정의하는지에 따라 알고리즘의 효율성이 달라진다.
예를 들어 8개의 배열에서 2개씩 4그룹으로 나누어 정렬한다. 그런 다음 이 두 그룹이 섞이지 않은 상태에서 다시 합친다면 배열은 원래대로 돌아온다.
이 문제를 해결하기 위해서는 h값이 서로 배수가 되지 않게 해야한다. 따라서 이 책에서는 3배에 +1을 하는 것이 좋다고 한다.
퀵정렬
퀵정렬은 가장 빠른 정렬 알고리즘이라고 알려져 있으며 널리 사용된다. 퀵정렬의 방법은 배열의 원소중 하나를 기준으로 세운 뒤 기준 값을 넘는 그룹과 넘지 않는 그룹 두가지로 나눈다. 이 때 기준이 되는 원소를 피벗이라 한다.
이 방법을 끝까지 하다보면 배열은 자연스럽게 정렬되는데 이 방법에서 재귀가 사용된다. 아래 그림에서는 피벗값이 5일 떄 퀵정렬이다.
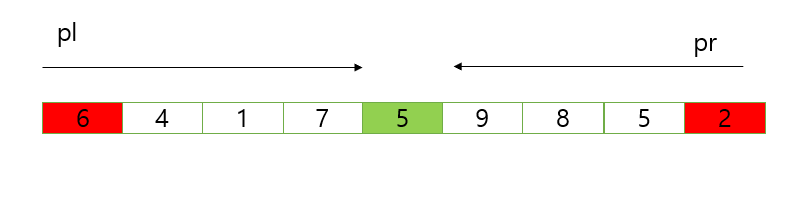
이 때 pl은 항상 피벗값보다 작아야하고 pr은 항상 피벗값보다 커야한다. 이 때 pl이 5보다 큰 수를 만나거나 pr이 5보다 작은 수를 만났을 때 두 값을 교환하며 배열을 조정한다.
다음은 퀵정렬의 코드이다.
def qsort(a: list, left: int, right: int) -> None:
pl = left
pr = right
x = a[(left + right) // 2]
while pl <= pr:
while a[pl] < x: pl += 1
while a[pr] > x: pr -= 1
if pl <= pr:
a[pl], a[pr] = a[pr], a[pl]
pl += 1
pr -= 1
if left < pr:
qsort(a, left, pr)
if pl < right:
qsort(a, pl, right)
def quick_sort(a: list) -> None:
n = len(a) - 1
qsort(a, 0, n)
if __name__ == '__main__':
print('퀵 정렬을 수행합니다.')
num = int(input('원소 수를 입력하세요.: '))
x = [None] * num
for i in range(num):
x[i] = int(input(f'x[{i}]: '))
quick_sort(x)
print('오름차순으로 정렬했습니다.')
for i in range(num):
print(f'x[{i}] = {x[i]}')퀵정렬에서 주의해야 할 점은 피벗을 선택하는 방법이다. 예를 들어 10이 가장 큰 원소인 배열에서 피벗을 10으로 잡는다면 아무 의미없는 작업만 할 뿐이다.
이 때 가장 효율적인 방법은 다음과 같다.
- 배열의 원소 수가 3 이상일 때 임의의 원소 3개를 꺼내 중앙값인 원소를 피벗으로 설정하는 방법
- 배열의 첫번째값, 중간값, 마지막값을 정렬해 중간값을 마지막값의 인덱스 바로 앞에 두고 pl을 중간값보다 한 칸 앞에서 스캔을 시작하게 하는 방법이다. 그렇게 하면 2개의 범위값을 줄일 수 있다.
또한 퀵정렬은 배열의 크기가 작을 때 그렇게 좋은 알고리즘이 아니다. 따라서 배열의 크기가 작을 때에는 앞서 배운 단순 삽입정렬이나 다른 알고리즘을 이용하는것이 더 효율적이다.
'Algorithm > 자료구조와 함께 배우는 알고리즘' 카테고리의 다른 글
| 정렬 알고리즘 (fin) - 도수정렬 (0) | 2022.08.03 |
|---|---|
| 정렬 알고리즘 (3) - 병합정렬, 힙정렬 (0) | 2022.08.03 |
| 정렬 알고리즘 (1) - 버블정렬, 단순 선택/삽입 정렬 (0) | 2022.07.28 |
| 재귀 알고리즘 (2) - (하노이의 탑, 8퀸 문제) (0) | 2022.07.27 |
| 재귀 알고리즘 (1) (0) | 2022.07.27 |




댓글